How DeepSeek V4's 90% KV Cache Reduction Reshapes HBM Demand — From Capacity to Bandwidth, Packaging, and Thermal Control
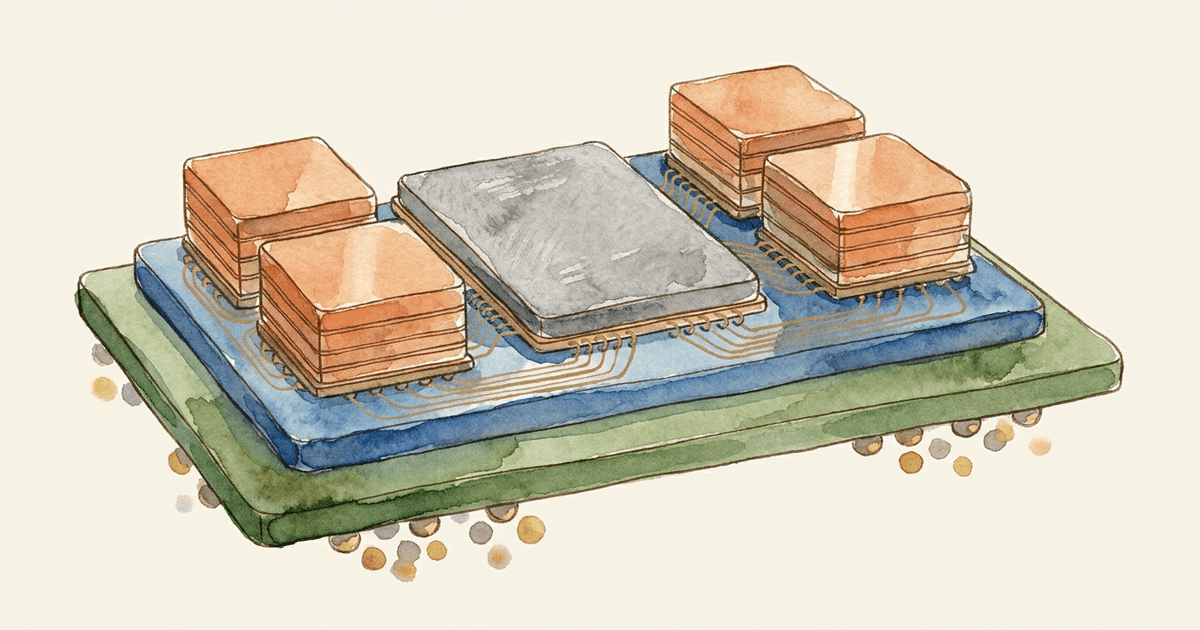
Introduction: What “90% KV Cache Reduction at 1M Tokens” Actually Means
With OpenAI’s GPT-5.5 and Anthropic’s Claude Opus 4.7, the latest generation of models has begun to act as autonomous “AI agents” that handle complex tasks. As a result, the context an AI processes at one time has grown rapidly. The “memory wall” — limits on memory capacity and bandwidth — has become a real, day-to-day operational problem.
KV cache compression techniques like Google’s TurboQuant have drawn attention as a response. Among them, DeepSeek V4’s claim of a 90% KV cache reduction at 1M tokens, covered by Reuters, stands out as a major efficiency leap on the software side (official details are on the Hugging Face model card).
A natural question follows: if memory consumption drops sharply on the software side, does that destroy demand for HBM (high-bandwidth memory), the long-time star of AI infrastructure?
I will argue something different. In my view, DeepSeek V4’s KV compression does not erase HBM demand — it fundamentally changes what HBM is valued for.
The simple story is this: until now, raw “data capacity (GB)” was the centerpiece. From here, value moves toward “bandwidth (GB/s)”, “I/O pin density”, and the packaging, thermal control, and yield management that support them.
What DeepSeek V4 Actually Delivered
Model lineup and compression effect
DeepSeek V4 has been released as a preview with two models. Both support 1M-token context.
| Item | V4-Pro | V4-Flash |
|---|---|---|
| Total parameters | 1.6T | 284B |
| Active parameters | 49B | 13B |
| Context length | 1M tokens | 1M tokens |
| Single-token inference FLOPs (vs. V3.2) | 27% | 10% |
| KV cache size (vs. V3.2) | 10% | 7% |
DeepSeek identified the attention mechanism as the main bottleneck for long-context processing. V4 introduces a hybrid that alternates between CSA (Compressed Sparse Attention) and HCA (Heavily Compressed Attention).
- CSA: compresses every tokens into one KV entry, then applies sparse attention.
- HCA: compresses a much wider range of tokens () into a single, heavily compressed entry.
These gains are per-request, not data-center-wide
An important caveat: these efficiency numbers are per single inference. They do not directly translate into “the entire data center needs 90% less HBM.” The actual hardware impact depends on where the freed-up HBM headroom goes:
- A: process even longer contexts on the same GPU
- B: keep the same context length but increase concurrent sessions (parallelism)
- C: simply reduce the number of GPUs deployed and cut cost
On-disk KV cache: a tiered-memory architecture
Equally important is that DeepSeek explicitly built an on-disk KV cache into the system. When multiple users request the same shared system prompt (a shared prefix), V4 stores the compressed CSA/HCA KV on SSD to skip re-prefill, and reuses it on cache hit. The non-compressed SWA (Sliding Window Attention) KV is roughly 8x larger, so the system uses three modes — full caching, periodic checkpointing, and zero caching — depending on the workload.
This means V4 is not just “a model that saves HBM.” It is an architecture designed around tiered memory across HBM, SSD, and NAND.
Implementation: NVIDIA in public, Huawei in production
There are two faces to V4’s deployment:
- Public stack (NVIDIA-centric): optimization libraries on GitHub like FlashMLA, DeepGEMM, and DeepEP are still heavily tuned for NVIDIA GPUs (Hopper, Blackwell).
- Production (adapting to a domestic Chinese stack): Reuters reports that DeepSeek V4 is fully supported on Huawei Ascend 950-series supernodes, and parts of V4-Flash training used Huawei chips.
The most reasonable read today is that the published code looks NVIDIA-first while the actual production stack is moving quickly toward domestic alternatives.
Quality claims deserve some skepticism
V4 scores well on long-context tests like LongMRCR and CorpusQA. But for the coding-agent evaluation, DeepSeek used its own framework: bash plus file-edit tools only, capped at 512K context and 500 steps, with about 200 internal R&D tasks and a survey of 85 internal users.
The setup is realistic for production, but it leaves room for bias compared to fully independent benchmarks. Reuters also notes V4 does not yet support image or video. My read: the KV compression is very promising on efficiency, but full quality preservation is still waiting on third-party verification.
How the Software Efficiency Reshapes HBM Demand
Causal tree: how a single efficiency gain moves the demand structure
The chart below shows how DeepSeek’s KV reduction propagates through the hardware market.
flowchart TD
A["DeepSeek V4<br/>KV cache compression"]
B["Per-request KV capacity ↓"]
C["Attention FLOPs ↓"]
D["Longer context per HBM"]
E["More sessions per HBM"]
F["Capacity-only premium ↓"]
G["Per-request inference cost ↓"]
H["Agentic / RAG / 1M context<br/>becomes economical"]
I(("Total inference volume<br/>explodes"))
J["HBM value moves to<br/>bandwidth · thermal · packaging"]
K["HBM4 / TSV / interposer /<br/>CoWoS = real bottleneck"]
L["Spillover to SSD / CXL / HBF"]
M["Lower tier absorbs capacity"]
A --> B
A --> C
B --> D
B --> E
B --> F
C --> G
D --> H
E --> H
G --> H
H --> I
F --> J
J --> K
B --> L
L --> M
classDef primary fill:#e1f5fe,stroke:#0288d1,stroke-width:2px;
classDef secondary fill:#f3e5f5,stroke:#8e24aa;
classDef bottleneck fill:#ffebee,stroke:#c62828,stroke-width:2px;
class A primary;
class B,C,D,E,F,G,L,M secondary;
class H,I primary;
class J,K bottleneck;Two flows run in parallel: on the right, HBM value migrates toward bandwidth, thermal, and packaging, and at the bottom, on-disk KV pushes demand into the lower memory tiers.
Memory hierarchy is being reorganized as a whole
DeepSeek’s design assumes a role split across the entire memory hierarchy, not HBM optimization in isolation.
flowchart TD
GPU["GPU<br/>compute"]
HBM["HBM<br/>capacity × bandwidth"]
CXL["CXL DRAM<br/>warm tier"]
HBF["HBF<br/>8–16x capacity"]
SSD["SSD / NAND<br/>on-disk KV"]
GPU <==>|TB/s| HBM
HBM <-->|pooled| CXL
HBM <-->|Tier 2| HBF
HBM -.->|overflow| SSD
classDef hot fill:#ffe0e0,stroke:#c62828,stroke-width:2px;
classDef warm fill:#fff8e0,stroke:#f57c00;
classDef cold fill:#e0f2f1,stroke:#00796b;
class GPU,HBM hot;
class CXL,HBF warm;
class SSD cold;HBM stays on top (Hot), but warm/cold tiers — CXL DRAM, HBF, SSD — emerge underneath, and KV data flows through them based on type and access frequency. This is not the death of HBM. It is a reorganization of the entire memory hierarchy with HBM at the apex.
Five core takeaways
- (Short term) KV compression lowers per-request HBM capacity demand. But in the actual 2026 market, both HBM supply and advanced packaging supply are still tight, so total demand does not break overnight.
- (Medium term) Memory value shifts from “GB per stack” to “bandwidth, I/O, TSV, interposer, underfill, thermal, and yield.” HBM4 and advanced packaging matter more, not less.
- (Long term) HBF, CXL, on-disk KV, and near-memory compute become mainstream. They complement HBM at lower capacity tiers rather than replace it.
- (Biggest winners) Not memory makers alone — advanced packaging, substrate materials, thermal materials, and metrology capture the most value.
- (Biggest unknown) Whether DeepSeek V4’s claims survive independent reproduction, and whether the cost reduction truly translates into a demand explosion (DeepSeek’s agent evaluation includes a non-trivial share of internal tools and tasks).
The Economics of Inference and Training
Direct effect on inference
The benefit of KV cache reduction shows up most directly in inference. When a decoder-only LLM generates tokens, each step requires reading the model weights plus the conversation history (KV cache). The longer the context, the more KV capacity and bandwidth consumed.
DeepSeek V4 cuts a large portion of that read and compute. On GPUs with large HBM like the NVIDIA H200, the freed headroom is most easily redirected into larger batches, longer contexts, or faster token generation.
NVIDIA positions the H200 around “141 GB of HBM3e and 4.8 TB/s of bandwidth.” Micron markets its HBM3E (24 GB / 36 GB) with “over 1.2 TB/s bandwidth” and “50% more queries served.” The market still puts a real premium on the physical presence and speed of HBM.
Limits on the training side
Training is a different story. The dominant memory consumers during training are parameters, gradients, optimizer state, and activations. DeepSeek itself uses context parallelism and tensor-level checkpointing to handle these.
V4’s KV compression helps with long-context communication during training, but it is not a magic wand that makes HBM unnecessary for training. Large-capacity, high-bandwidth HBM stays at the core of training infrastructure.
A simple TCO model
Here is a simplified estimate of effective TCO impact for a cluster operator.
- Let be the share of total inference time attributable to KV cache.
- Assume KV-related data volume drops 90% as DeepSeek claims.
- Then latency improvement is approximately .
Applied to real workloads:
| Workload | Estimated KV load share | Latency improvement (≈) |
|---|---|---|
| Short-context chat | 10–20% | 9–18% |
| Long-context RAG / agent | 30–60% | 27–54% |
Workload bottlenecks and HBM demand
| Workload | Typical bottleneck | KV compression benefit | First-order HBM demand effect | Comment |
|---|---|---|---|---|
| Short-context chat | Weight loading, low-parallel decode | Small to medium | Slightly bearish to neutral | Low KV share, so HBM reduction is limited. Headroom often goes to more concurrent sessions, not cost cuts |
| Long-context RAG | KV capacity, KV bandwidth, prefill/decode imbalance | Large | Neutral to bullish | 1M-token contexts and prompt reuse become economical, total inference grows |
| Agentic tasks (coding, etc.) | Long context + multi-step tools + shared prefix | Large | Bullish | Per-task token consumption is far higher; lower unit cost translates directly into more usage |
| Pretraining / large-scale RL | Activations, gradients, optimizer state, bandwidth | Small | Neutral | KV compression is auxiliary in training; HBM remains central |
The key insight: DeepSeek V4 acts more as a force that changes how HBM is used than one that reduces total HBM. NVIDIA’s GB200 NVL72 and Blackwell Ultra architectures push trillion-parameter real-time inference and Agentic AI, supported by NVLink fabric, high-bandwidth memory, and water cooling. Even with smarter models and compressed KV, the data center design philosophy points toward using freed headroom for harder workloads, not for ripping HBM out to save money.
Decomposing HBM: Where Does the Value Actually Move?
To see HBM’s real value clearly, drop the picture of “a memory chip with lots of capacity.” HBM is a composite product where capacity, bandwidth, I/O pins, stacking, packaging, thermal, and yield are fused at the limit.
The latest product specs confirm this:
| Vendor | Product | Capacity | Bandwidth | Pins |
|---|---|---|---|---|
| Samsung HBM4 | HBM4 | 36 GB | up to 3,300 GB/s | 2,048 I/O · up to 13 Gbps |
| Micron HBM3E | HBM3E | 24 GB / 36 GB | over 1.2 TB/s | — |
Marketing has clearly shifted from “GB per stack” toward “GB/s per stack” — bandwidth is now part of the headline.
HBM does not work as a standalone DRAM chip
What matters even more is that HBM does not function as a standalone DRAM chip. TSMC’s CoWoS-S places HBM cubes alongside logic dies on a large silicon interposer and connects them with extremely fine wiring. Applied Materials reports that HBM manufacturing requires roughly 19 additional materials-engineering steps compared to standard DRAM, including TSV, barrier/seed layers, microbumps, and die-warpage control.
Thermally, stacking 12 layers or more triggers a sharp rise in thermal resistance. Specialized molding compounds (MR-MUF) and thermal spreaders become essential.
The real BOM of HBM looks like this composite stack:
flowchart TB
subgraph S1["Inside the HBM stack"]
DRAM["DRAM × 12–16 layers"]
BASE["Base die"]
TSV["TSV<br/>through-silicon via"]
BUMP["Microbumps"]
UF["Underfill<br/>MR-MUF / NCF"]
end
subgraph S2["Packaging"]
INT["Silicon interposer"]
SUB["ABF substrate"]
end
subgraph S3["Thermal"]
TIM["TIM"]
LID["Heat spreader"]
COOL["Water cooling"]
end
DRAM --> TSV
BASE --> TSV
TSV --> BUMP
BUMP --> UF
UF --> INT
INT --> SUB
SUB --> TIM
TIM --> LID
LID --> COOL
classDef inner fill:#e3f2fd,stroke:#1976d2;
classDef pkg fill:#fff3e0,stroke:#e65100,stroke-width:2px;
classDef thermal fill:#ffebee,stroke:#c62828;
class DRAM,BASE,TSV,BUMP,UF inner;
class INT,SUB pkg;
class TIM,LID,COOL thermal;HBM-adjacent infrastructure and KV-compression sensitivity
| Layer | Components | Process / materials | Upstream raw materials | Sensitivity to KV compression |
|---|---|---|---|---|
| DRAM stack | DRAM dies + base die | Advanced silicon process, stack-height control, logic-integrated base die | High-purity silicon wafers, front-end materials | Capacity-axis premium softens. Still core for training and high-bandwidth inference |
| TSV | Vertical micro-wiring | Insulating liner, barrier/seed, Cu plating, CMP | Oxide liner, TiN/WN barriers, Cu seed/fill, CMP slurry | Up. Critical as I/O count and pin speed jump with HBM4+ |
| Microbumps / pillars | Tiny die-to-die contacts | UBM, surface clean, fine bump formation | Cu wiring, Sn/Ag joining materials | Up. Connection density becomes the value, not capacity |
| Underfill / molding | MR-MUF, NCF, EMC | Heat and stress relief, warpage control | Epoxy resins, silica fillers | Up. Thermal/stress control is the binding constraint at scale |
| Silicon interposer | Bridge between GPU and HBM | RDL, TSV, backside metallization | Silicon wafers, Cu wiring, CMP materials | Up. CoWoS-class 2.5D limited by yield as area grows |
| Package substrate (ABF) | Build-up substrate | Fine line/space, multi-layer | Epoxy + curing agents + inorganic fillers, PET carrier | Up. Ajinomoto ABF dominates; difficulty grows with size and layer count |
| Thermal stack | TIM, lid, water-cooling module | Reduce interface thermal resistance, spread heat | Alumina, BN-class high-conductivity materials, cooling hardware | Up. Rack-level inference servers and standard liquid cooling lift the value sharply |
The more KV compression improves capacity efficiency, the more value migrates to how to route the wiring, how to control warpage, and how to dissipate heat. That migration is the core investment thesis of this piece.
Scenarios and Winners / Losers
Three scenarios
How the freed HBM headroom is used decides everything. The market has three plausible paths.
flowchart TD
A["Freed HBM headroom<br/>after KV compression"]
A --> B{"How is it used?"}
B -->|Cost-cut all-in| W["Bear case<br/>prob. low–med"]
B -->|Longer context · parallelism · RPS| N["Base case<br/>prob. med–high"]
B -->|New Agentic AI demand| S["Bull case<br/>prob. medium"]
W --> W1["HBM/GPU ↓<br/>capacity premium erodes"]
N --> N1["HBM4 / CoWoS / bandwidth<br/>= bottleneck"]
S --> S1["HBM + HBF + CXL<br/>expand together"]
classDef bear fill:#ffe0e0,stroke:#c62828;
classDef base fill:#fff8e0,stroke:#f57c00,stroke-width:2px;
classDef bull fill:#e0f2f1,stroke:#00796b;
class W,W1 bear;
class N,N1 base;
class S,S1 bull;Bear case (probability: low to medium)
Hyperscalers redirect all the freed headroom to “fewer GPUs and less HBM.” In a market dominated by short-context chat and flat inference growth, more workloads fit on 24 GB or 36 GB stacks, and the capacity premium collapses. Even here, advanced packaging vendors are not losers — bandwidth, thermal, and packaging hurdles still remain.
Base case (probability: medium to high)
Capacity demand softens slightly, but the freed headroom is redeployed into longer contexts, higher parallelism, and a sharp jump in requests-per-second on the same HBM. HBM TAM holds up. The real winners are not capacity-bidding memory makers, but vendors of HBM4, high-speed pin technology, CoWoS, fine metrology and yield management, and liquid-cooling materials. NVIDIA’s strong Agentic AI push with its latest architectures sits squarely on this trajectory.
Bull case (probability: medium)
KV compression does not just hold the line — it creates entirely new demand by shifting the demand curve to the right. With 1M-token inference at low cost, long-running autonomous agents, company-wide document search, and high-quality coding assistance become daily products. Per-task token consumption explodes, and total cluster demand grows sharply. HBF and CXL ride underneath, but HBM at the top remains an absolute infrastructure layer.
Supply chain ripple
| Layer | Key players | Role | KV compression impact | Real bottleneck |
|---|---|---|---|---|
| Memory | SK hynix, Samsung, Micron | HBM3E / HBM4 stack supply | Capacity premium softens; total demand holds or grows due to inference volume | Yield on advanced DRAM, 12–16 layer stacks, base-die sophistication |
| Foundry / packaging | TSMC, Amkor, ASE | Interposer fab, 2.5D / 3D integration, final test | Structural tailwind. Memory communication complexity raises packaging value | CoWoS / 3D-IC capacity shortage, large-area yield, long lead times |
| Equipment / metrology | Applied Materials, KLA, Lam Research | TSV formation, deposition, etch, inspection, warpage | Tailwind. Packaging difficulty forces investment in latest tools | Finer TSV, defect control, hybrid bonding maturity |
| Packaging materials | Ajinomoto (ABF), underfill makers | High-density substrate insulation, joint stress relief | Tailwind. Heat and stress control becomes the lifeline | Concentration risk on dominant suppliers, long qualification lead times |
| Lower-tier memory | Sandisk (HBF), CXL ecosystem | Capacity tier complementing HBM | Largest tailwind. Aligns perfectly with DeepSeek-style architecture | Software integration, effective latency, standardization speed |
The biggest bottleneck in 2026 is not HBM die output itself — it is the advanced packaging capacity to ship HBM together with GPUs. TSMC is rushing to bring up a new CoWoS plant in Arizona, and ASE expects its advanced packaging business to double.
Interaction with Alternative Memory Technologies
Looking at non-HBM memory technologies reinforces the base-to-bull case.
- HBF (High Bandwidth Flash): Sandisk and SK hynix are standardizing HBF with the goal of HBM-class bandwidth and 8–16x the capacity. This pairs directly with on-disk KV. HBF is not a competitor to HBM — it is a strong complement that absorbs capacity overflow at lower cost.
- CXL: CXL memory pooling shares memory across hosts. With KV compression, using premium HBM purely for “data sitting around” makes less sense; offloading warm data into a CXL DRAM tier becomes more rational.
- GDDR7: relatively more attractive in mid-tier inference. It does not match HBM on bandwidth density or efficiency, but KV compression widens the range of inference that runs fine without ultra-premium HBM, so GDDR7 gets a TCO-driven second look. It does not steal the frontier crown.
- Near-memory compute / HBM-PIM / hybrid bonding: more valuable, not less. Samsung’s HBM-PIM and Applied Materials’ hybrid bonding attack the physical cost of moving data. Even if capacity pressure eases, heat and power from data movement do not go away, so investment in these technologies remains sound.
Investment and Strategy Implications
| Position | Direction | Main thesis | KPIs to watch |
|---|---|---|---|
| Tier-1 winner | High-value HBM4-class memory, advanced packaging, fine metrology, thermal materials, substrates | Bandwidth, packaging density, and thermal design earn the premium, not capacity alone | HBM4 share of revenue, pin speed, CoWoS / 3D-IC line utilization |
| Tier-2 winner | CXL / HBF / fast SSD tiered infrastructure | Aligns precisely with DeepSeek-style tiered memory design | Prefix-cache hit rate, SSD read amplification, CXL pool deployments |
| Neutral to winner | GDDR7 ecosystem | TCO competitiveness in mid-range inference outside HBM | HBM vs. GDDR SKU mix on inference GPUs |
| Relative loser | ”Bigger capacity” as the only HBM differentiator | The pure-capacity premium is most exposed | Slowing growth in HBM capacity (GB) per GPU |
KPI checklist to track
- Continued strong guidance from memory vendors (e.g., SK hynix) that demand exceeds capacity
- New GPU pitches that move from “how many GB” to “bandwidth, I/O, water-cooling, rack-level inference”
- Continued large capex from TSMC, Amkor, ASE on CoWoS and 3D-IC capacity
- Field-level growth in tokens-per-task, average context length, and tool-call frequency (the litmus test for whether efficiency converts into more demand)
Open questions
- Independent verification of DeepSeek V4’s long-context quality is still insufficient.
- The published code stops at the lower-level communication layers; the actual production system stack DeepSeek runs is a black box.
- The strongest claim in this piece is not “HBM becomes unnecessary.” It is the structural shift: the value standard for HBM moves fully from capacity-led to bandwidth, packaging, and thermal-led.
Sources
- DeepSeek-V4-Pro model card (Hugging Face)
- Reuters: China’s DeepSeek returns with new model
- Reuters: DeepSeek V4 adapted to Huawei chips
- DeepSeek FlashMLA / DeepGEMM / DeepEP
- Samsung HBM / Micron HBM3E
- NVIDIA H200 / NVIDIA GB200 NVL72
- TSMC CoWoS
- Applied Materials: HBM materials innovation
- Applied Materials: Hybrid bonding
- KLA Advanced Packaging
- Ajinomoto ABF
- CXL: Memory Pooling and Sharing
- Sandisk × SK hynix: HBF standardization
- Reuters: SK hynix Q1 results
- Reuters: TSMC Arizona packaging plant
- Reuters: ASE advanced packaging
- Amkor 2.5D/3D TSV
Join the conversation on LinkedIn — share your thoughts and comments.
Discuss on LinkedIn