NerveReflex ― 非言語で協調するAIアーキテクチャの研究
課題
現在のAIシステムは、モデル同士を連携させるとき、多くの場合いったん人間の言葉に戻しています。あるモデルが文章を出力し、別のモデルがそれを読み直す。この方法は分かりやすい一方で、トークン生成による遅延、コスト、情報落ち、形式崩れを生みます。さらにLLMは、未学習の入力に対してももっともらしい答えを返しやすく、運用中の経験から自律的に学び直す仕組みもまだ弱いという課題があります。
解決策
NerveReflex は、AIモデル同士を非言語の内部表現で協調させるAIアーキテクチャです。人間の神経反射のように、言葉に変換する前の信号を低遅延で伝え、複数のモデルがそれぞれの強みを活かして推論・検知・判断を分担します。個々のモデルが持つ弱点を、別のモデルの強みで補完し合うことで、全体としてより速く、軽く、未学習の入力にも気づけ、経験から適応していけるAIシステムを作ることを目指します。
成果
NerveReflex の考え方を、法務契約レビューと Latent Reasoning で検証しました。法務契約のリスク分類では、SLM(Small Language Model。小型言語モデル)の内部表現を直接読むことで、トークン生成ゼロ・約 0.07 秒の構造化出力を実現しました。さらに同じ内部表現に JEPA(Joint Embedding Predictive Architecture。共同埋め込み予測アーキテクチャ)を重ねることで、通常分布から外れた条項を AUC 0.97 で検知できました。これは、内部表現を共有することで『高速な判断』と『未学習・異常への気づき』を別モジュールで補完できることを示しています。Latent Reasoning では、非言語の内部表現による推論により、同一問題を文字推論より約 14 倍高速に解けることを確認しました。
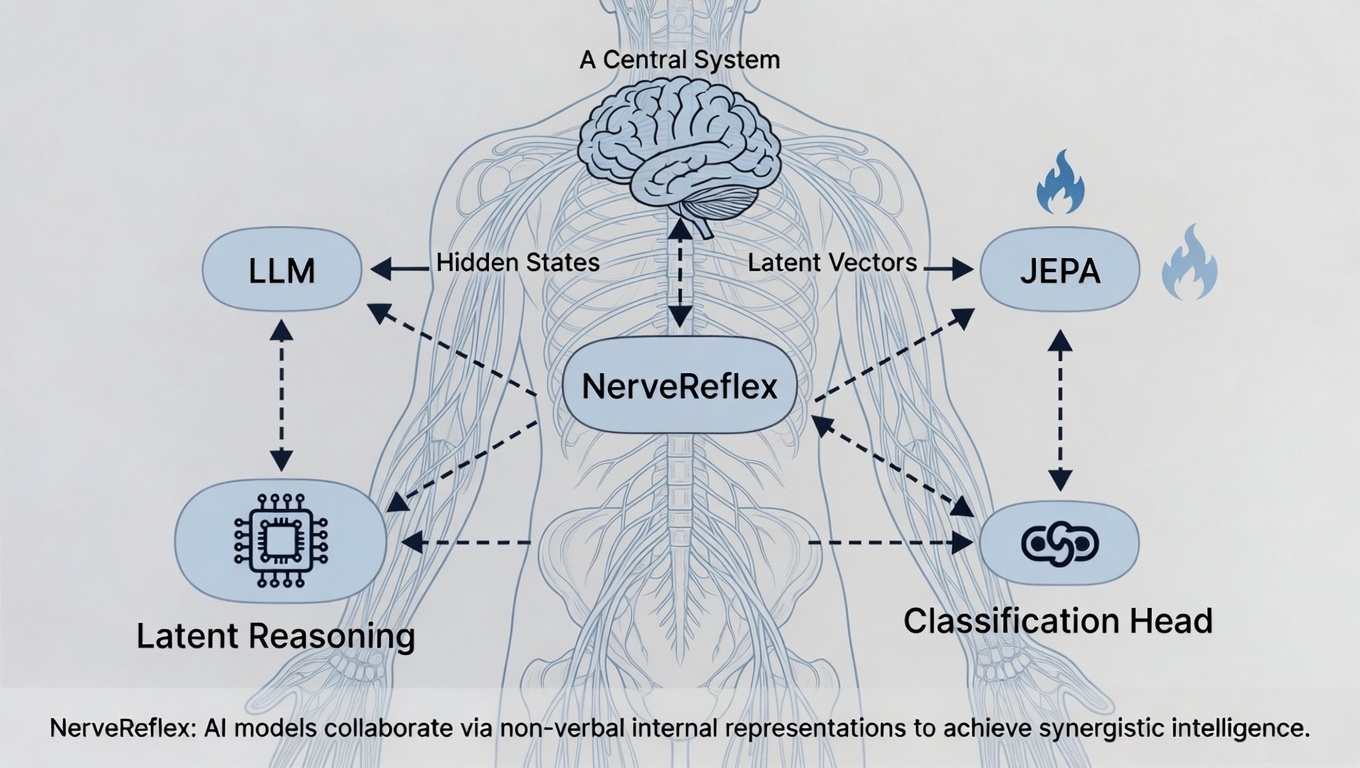
はじめに ― NerveReflexとは何か
本稿では、この方向性を NerveReflex と呼びます。
NerveReflex とは、神経回路のように、AIモデル同士を非言語の内部表現で協調させるAIアーキテクチャです。
人間の体は、すべてを言葉にしてから動いているわけではありません。
熱いものに触れた瞬間に手を引く。転びそうになった瞬間に足が出る。ボールが飛んできた瞬間に体が反応する。
これらは、言葉で考えてから起きているわけではありません。神経回路が低遅延で信号を伝え、脳、神経、筋肉が協調して一つの目的を達成しています。
NerveReflex は、この発想をAIアーキテクチャに持ち込む試みです。
AIが理解した内容を、いったん人間の言葉に戻すのではなく、hidden state(隠れ状態。モデルが入力を処理した結果として内部に持つ数値表現)や latent vector(潜在ベクトル。意味や特徴を圧縮した内部表現)のまま扱います。
そして、その内部表現を使って、推論、分類、異常検知、判断、モデル間の協調を行います。
これは、既存のLLMやTransformerを否定するものではありません。
むしろ、LLMやTransformerの強みを前提にしています。LLMには、言語理解、知識の圧縮、文章生成、コード生成において圧倒的な強みがあります。一方で、World Model(世界モデル。外界や文脈の状態を内部に表現し、次に何が起こるかを予測するモデル)には世界の状態予測やサプライズ検知の強みがあり、Latent Reasoning(潜在推論。思考過程を文字として出さず、内部表現のまま進める推論)には非言語の高速推論の可能性があります。進化的な学習モデルには、経験から適応していく可能性があります。
重要なのは、どれか一つが他を完全に置き換えることではありません。
NerveReflex が目指すのは、それぞれのモデルを単体で競わせることではなく、言葉を介さない内部表現のレイヤーで協調させること です。
ここで重要なのは、協調の目的が単なる高速化だけではない、という点です。
LLMには、言語理解や知識処理において大きな強みがあります。一方で、学習していない入力に対して「分からない」と判断することは苦手であり、運用中の経験から自律的に学び直す仕組みもまだ弱いという課題があります。
そこで、LLMやSLMが作った内部表現に対して、JEPAのようなモデルを非言語で連携させます。JEPAは、入力が学習済みの正常な分布からどれだけ外れているかを energy として測ることができます。つまり、LLM単体ではもっともらしい答えを返してしまう場面でも、別のモデルが「これは未学習に近い」「これは通常と違う」と検知できる可能性があります。
さらに、そのような高 energy の入力を蓄積すれば、現場で新しく出てきた事例を拾い、再学習や適応の候補にできます。これは、固定されたLLM単体では実現しにくい、進化的な学習への入口になります。
つまり NerveReflex は、個々のモデルの弱点を、別のモデルの強みで補う設計です。LLMが苦手な未学習入力への対応を JEPA が補い、文字推論の遅さを Latent Reasoning が補い、定型判断の重さを分類ヘッドが補う。このように複数のモデルが内部表現上で協調すれば、単体モデルのデメリットを減らしながら、それぞれのメリットを活かす仕組みを作れる可能性があります。
言い換えれば、これは「巨大な一つのモデルを作る」研究ではなく、複数の知能モジュールが神経回路のように連携し、互いの弱点を補完するAIアーキテクチャ の研究です。
なぜ「言葉に戻す」ことが問題になるのか
現在のAIエージェントやマルチモデル構成では、モデル同士のやり取りに自然言語が使われることが多いです。
たとえば、あるモデルが契約書を読んで「この条項は中程度のリスクです」と文章で出力する。次のモデルがその文章を読み、さらに別の判断をする。
これは人間には分かりやすい一方で、AIシステムとして見ると無駄が多くなります。
第一に、文字を生成するには時間がかかります。LLMは通常、1トークンずつ順番に文字を出力します。短いJSONを出すだけでも、何十回もモデルを動かす必要があります。
第二に、トークン生成にはコストがかかります。企業がAIを業務に使うほど、入力トークン、出力トークン、長い会話履歴、エージェントの試行錯誤によって費用が膨らみます。
第三に、文章に戻すと情報が落ちます。モデル内部には、文脈、意味、構造、曖昧さ、確信度のような情報が高次元の内部表現として存在しています。しかし、それを短い文章にすると、情報の一部は失われます。
第四に、形式が壊れます。JSONを出してほしいのに、コードブロックが付いたり、余計な説明が混ざったり、パースできない形式になることがあります。
つまり、AI同士を連携させるたびに人間の言葉へ戻す設計は、分かりやすいですが、遅く、重く、不安定になりがちです。
NerveReflex は、この部分を変えます。
モデルが理解した内容を、毎回文字に変換するのではなく、内部表現のまま次の処理へ渡す。必要なときだけ言葉にする。そうすることで、低遅延で、軽く、より安定したAIシステムを作れないかを検証します。
NerveReflexの基本方針
NerveReflex の基本方針は、既存モデルの強みを活かしながら、言語化が不要な部分を切り分けることです。
たとえば、SLM は文章や画像を意味として理解する能力を持っています。この能力は使います。
しかし、理解した内容を毎回 LM Head(Language Model Head。内部表現を語彙ごとの確率に変換し、次のトークンを選ぶ最終層)に渡し、文字として出力する必要はありません。
通常の LLM は、hidden state を LM Head へ渡して文字を生成します。
NerveReflex では、必要な場面以外では LM Head をバイパスします。
つまり、モデルが入力を理解した結果である hidden state を直接使います。その上に分類ヘッドを載せたり、JEPA で異常検知をしたり、別のモデルへ渡したりします。
ここでいう JEPA は、画像や文章をそのまま生成するのではなく、低次元の意味空間で「次に何が起こるか」「この状態は自然か」を予測するモデルです。
NerveReflex の考え方を整理すると、次のようになります。
- 理解: SLM や LLM が入力を読み、hidden state として内部表現を作る。
- 判断: 分類ヘッドが hidden state から必要なラベルや構造化情報を読む。
- 検知: JEPA や energy-based model が、内部表現が正常な分布から外れていないかを見る。
- 推論: Latent Reasoning が、文字に展開せず latent vector のまま思考を進める。
- 協調: 異なるモデルやモジュールが、自然言語ではなく内部表現を介して連携する。
これは、単に既存モデルを横に並べる話ではありません。
目指しているのは、AIモデル同士が 神経回路のような内部信号 で協調する設計です。
第一歩: 世界を予測するモデル ― LeWorldModelの検証
最初の研究対象は、LeWorldModel(JEPA World Model) でした。
LLM は、基本的に次のトークンを予測します。つまり、文章の続きを文字列として生成します。
一方、LeWorldModel はピクセルや文字を直接生成しません。世界の状態を latent space(潜在空間。高次元の入力を圧縮した意味表現の空間)に写し、その空間上で「次にどうなるか」を予測します。
特徴は次の通りです。
- ピクセルや文字を生成するのではなく、低次元の潜在空間で未来を予測する。
- 約 15M パラメータの小さなモデルで、単一 GPU でも扱える。
- PushT という物理タスクを、潜在空間での計画によって解く。
PushT は、T字型のブロックを目標位置まで押すタスクです。人間から見れば単純に見えますが、AIにとっては物体の位置、向き、接触、力のかかり方を理解する必要があります。
このタスクでは、CEM(Cross-Entropy Method。複数の行動候補を試し、良さそうな候補を残しながら計画を改善する最適化手法)を使って、潜在空間上で行動を計画します。
公開されている学習済みサンプルモデルを、手元の単一 GPU で動かしたところ、PushT タスクで成功率 94% の動作を確認できました。
予測とサプライズ検知
LeWorldModel の価値は、大きく2つあります。
1つ目は、予測です。
「今の状態がこうなら、次はこうなるはずだ」という未来予測を、文字ではなく潜在空間で行います。これは World Model の中核です。
2つ目は、サプライズ検知です。
ここでいうサプライズとは、「学習した世界から見て、どれくらい不自然か」を意味します。JEPA や energy-based model(エネルギーベースモデル。ある状態や組み合わせがどれだけ自然かを energy というスコアで測るモデル)では、不自然な状態ほど energy が高くなります。
つまり、モデルは未来を予測するだけでなく、物理的・文脈的にあり得ない出来事を検知できます。
これは NerveReflex の重要な部品になり得ます。
神経反射でも、身体は異常な刺激に即座に反応します。熱いものに触れた瞬間、言葉で考える前に手を引く。同じように、AIシステムでも、内部表現が正常な分布から外れた瞬間に、軽量な検知モジュールが反応する設計が考えられます。
応用: 業務文書を内部表現で評価する
World Model というと、物理世界やロボティクスのイメージが強いです。
しかし、NerveReflex の発想は業務文書にも応用できます。
契約書、申請書、稟議書、ログ、問い合わせ内容には、それぞれ「通常のパターン」があります。文章として見れば複雑でも、内部表現として見れば、正常な分布とそこから外れた分布を区別できる可能性があります。
そこで、最初の業務応用として法務契約レビューを試しました。
流れは次の通りです。
まず、契約条項を SLM である Gemma に入力します。Gemma は文章を読み取り、hidden state、つまり内部表現を作ります。
通常であれば、この hidden state は LM Head に渡され、次のトークンとして文字に変換されます。しかし今回の目的は文章生成ではありません。契約条項が通常のパターンから外れているかを見たいわけです。
そこで、Gemma が作った内部表現を JEPA に渡し、JEPA 側で energy を測ります。
役割分担は次のようになります。
- SLM(Gemma): 契約条項を読み、内部表現に変換する。
- JEPA: その内部表現が、正常な契約条項の分布からどれくらい外れているかを energy として測る。
つまり、文章理解は SLM、異常検知は JEPA が担当する構成です。
この実験では、「正常な契約条項」と「異常な条項」を energy で分離できるかを確認しました。その結果、AUC 0.97 で分離できることを確認しました。
AUC は、分類モデルが正常と異常をどれだけうまく分けられるかを示す指標です。1.0 に近いほど分離性能が高く、0.5 はランダムに近い状態を意味します。
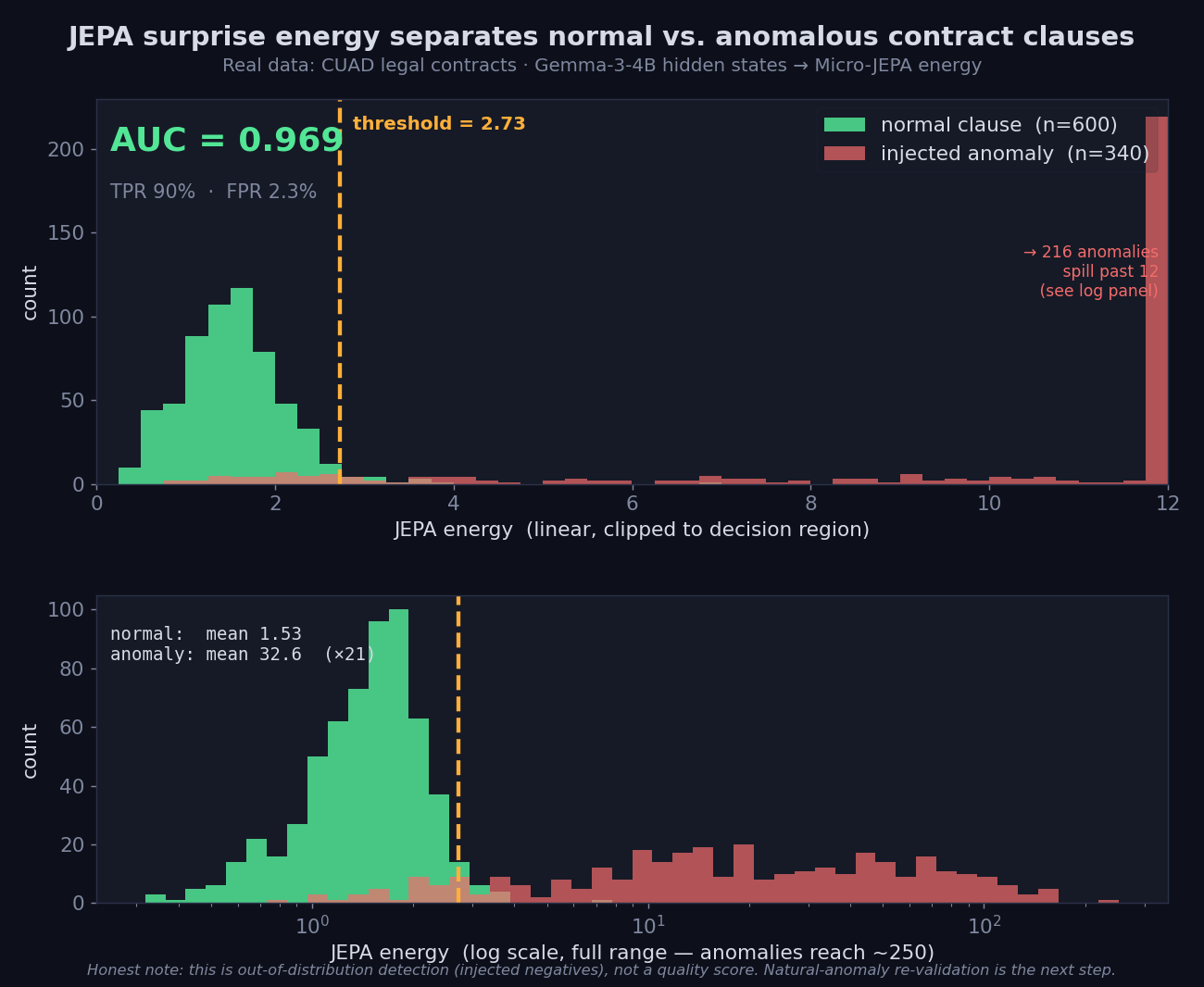
正常な条項はほとんどが低い energy に集まり、異常な条項は高い energy 側まで広がりました。しきい値を設定することで、AUC 0.97、TPR(異常を正しく検知する割合)90%、FPR(正常を誤って弾く割合)2.3% という分離性能になりました。
ただし、これは「契約の良し悪し」を採点するものではありません。
見ているのは、あくまで「正常な分布から外れているか」です。また、異常データは人工的に作って混ぜたものなので、自然な異常データでの再検証は必要です。
それでも、SLM と JEPA を内部表現上で組み合わせることで、業務文書を文字生成なしに評価できる可能性は見えました。
文字を出さずに分類する ― LM Headを通らない判断
次に試したのは、同じ契約条項のリスク分類です。
通常の方法では、Gemma に次のように頼みます。
「この条項を分類して、結果を JSON で出してください」
すると Gemma は、{"risk_level": "medium", ...} のような JSON を文字として生成します。これは普通の LLM の使い方です。
しかし、NerveReflex では別の方法を取ります。
同じ条項を Gemma に通し、得られた hidden state を取り出します。そして、その hidden state を小さな分類ヘッドに渡します。分類ヘッドは、risk_level、clause_type、needs_review のような項目を直接予測します。
この方式では、モデルは JSON という文字列を生成していません。
Gemma が条項を理解した結果である内部表現を、分類ヘッドが読み取っているだけです。最後の JSON は、プログラム側が確定的に組み立てます。
比較すると次のようになります。
| 比較項目 | 素の Gemma(文字で出力) | NerveReflex(内部表現で分類) |
|---|---|---|
| 出力の出し方 | JSON を文字として生成する | hidden state を分類ヘッドに通す |
| risk_level の結果 | medium(正解) | medium(正解) |
| 生成トークン | 37 トークン | 0 トークン |
| モデル実行回数 | 38 回(1 prefill + 37 decode) | 1 回 |
| 所要時間 | 約 5 秒 | 約 0.07 秒 |
| 出力形式 | 自由文。要パース。崩れうる | 構造化 JSON。パース不要 |
ここで重要なのは、賢さではありません。
同じ答えが出るのに、片方はトークンを1つも生成していない、という点です。
左の方式では、短い JSON であっても1トークンずつ順番に生成する必要があります。しかも、コードブロックや余計な説明が混ざることもあります。
右の方式では、Gemma が理解した結果である hidden state を1回読むだけで、同じ分類結果が得られます。出力形式もプログラム側で確定するため、壊れにくくなります。
業務で重要なのは、こうした分類、抽出、検知が大量に走ることです。1件あたりの言語化コストを減らせれば、全体のコストとレイテンシは大きく下がります。
さらに重要なのは、同じ hidden state の上に、別のモジュールを重ねられることです。
分類ヘッドは「この条項はどのリスク分類か」を読みます。一方、JEPA は「この条項は正常な分布から外れていないか」を見ます。
つまり、同じ内部表現に対して、分類と異常検知という異なる判断を重ねられます。
これは NerveReflex の中心的な考え方です。
単一のモデルがすべてを言葉で出力するのではなく、内部表現の上に複数の専門モジュールが協調して反応する。
第二歩: 文字でなく内部表現で推論する ― Latent Reasoning
次の手がかりは、推論そのものを文字から切り離すことでした。
通常の reasoning モデルは、答えを出す前に長い思考過程を書きます。たとえば DeepSeek-R1 のようなモデルは、何百から何千トークンもの reasoning trace(推論過程)を文字として出力し、その後に最終回答を出します。
この方式は強力です。
文字として考えることで、途中の計算、仮説、修正、検算を明示できます。人間にも読みやすく、自己修正もしやすい方式です。
一方で、弱点もあります。
文字で考える以上、考えれば考えるほどトークンが増えます。出力が長くなり、遅くなり、推論コストも増えます。
これに対し、Latent Reasoning(潜在推論。思考過程を文字として出力せず、hidden state や latent vector のような内部表現のまま進める推論)は、思考を文字として出力せず、内部表現のまま進めるアプローチです。
代表例の一つが CODI です。CODI は、推論の途中過程を自然言語トークンとして展開するのではなく、連続的な latent vector として扱います。
ポイントは次の2つです。
- 思考を文字に展開せず、latent thought(潜在的な思考ベクトル)のまま進める。
- 最後に答えだけを言語トークンとして出力する。
つまり、画面上には長い思考過程が出ません。モデルは内部で短い latent step を進め、最後に答えだけを出します。
これは、NerveReflex の考え方と近いものです。
すべてを文字に戻さず、内部表現で処理できるところは内部表現のまま進める。必要なときだけ言語化する。
動画で見る ― 同じ問題、同じGPU
※ この動画のモデルは CODI の公開学習済みチェックポイント(Llama-3.2-1B ベース)です。モデル自体は CODI 著者チームの成果であり、本稿ではそれを動作確認・速度計測しました。
| 比較項目 | Token CoT(文字で推論) | Latent(内部表現で推論) |
|---|---|---|
| 推論方法 | 215 トークンの思考を文字として書き出す | 6つの latent vector で内部的に推論する |
| 出力 | 思考過程を出した後、答え 18 を出力 | 答え 18 だけを即座に出力 |
| 結果 | 正解 | 正解 |
| 速度 | 約 3.4 秒 | 約 0.25 秒 |
| 速度差 | 基準 | 約 14 倍速い |
右側の Latent Reasoning は、「黙って考えて、答えだけ言葉にする」方式です。
左側の Token CoT がまだ思考を書いている間に、右側はすでに答えを出しています。この差が、文字に展開しない推論の速度優位を示しています。
ただし、Latent Reasoning は万能ではありません。
文字推論には、途中で計算を書き直したり、別の方針を試したり、検算したりする強みがあります。難しい問題では、この明示的な自己修正が効きます。
一方、Latent Reasoning では、思考ステップ数が固定されることが多いです。短い推論には向いていますが、長い検討や複数段階の問題では不利になることがあります。
つまり、Latent Reasoning は文字推論の完全な代替ではありません。
しかし、短い推論、分類、ルーティング、異常検知、簡単な判断のように、速度が重要な場面では有効な部品になり得ます。
NerveReflex では、こうした Latent Reasoning を、神経反射的な内部処理の一部として位置づけます。
NerveReflexが目指すもの
ここまでの実験は、一つの方向に収束しています。
NerveReflex が目指すのは、巨大な一つの汎用モデルを作ることではありません。
また、既存モデルを単に横に並べることでもありません。
目指しているのは、AIモデル同士が、言葉を介さず、内部表現のまま協調するアーキテクチャ です。
人間の体では、脳、神経、筋肉、感覚器官がそれぞれ異なる役割を持ちながら、一つの目的に向かって協調しています。すべてを言葉で説明し合っているわけではありません。神経信号を通じて、低遅延で反応しています。
NerveReflex も同じ発想を取ります。
- あるモデルは文章や画像を理解する。
- あるモジュールは分類する。
- あるモジュールは異常を検知する。
- あるモジュールは内部表現のまま短い推論を行う。
- あるモジュールは、経験から外れた入力を拾い、学び直しの候補にする。
これらを自然言語で逐一つなぐのではなく、内部表現のレイヤーで協調させます。
この考え方が成立すれば、既存モデルの応用だけでなく、新しいモデル設計にもつながる可能性があります。
たとえば、最初から「言語生成」を中心に置くのではなく、内部表現の伝達、反射的な検知、低遅延な判断、経験からの適応を前提にしたモデルです。
これは、LLM の次をすぐに置き換える話ではありません。
LLM は今後も重要です。言語理解、知識処理、説明生成、コード生成では、LLM の強みは大きいままです。
しかし、AIシステムのすべての処理を LLM の文字生成に任せる必要はありません。
NerveReflex は、LLM の周辺に、World Model、JEPA、Latent Reasoning、進化的な学習モジュールを配置し、内部表現で協調させることで、より軽く、速く、現場に近い AI システムを作る試みです。
まだ検証段階である
もちろん、これはまだ完成したアーキテクチャではありません。
現時点では、仮説と部分的な実験結果を積み上げている段階です。
最大の技術課題は、異なるモデル間で内部表現をどう揃えるかです。
あるモデルの hidden state と、別のモデルの hidden state は、同じ「内部表現」に見えても、その座標系は一致していません。そのまま接続しても、意味が通じるとは限りません。
このため、latent space alignment(潜在空間アライメント。異なるモデルの内部表現を対応づける処理)が必要になります。
また、過去には「専門 LoRA を単純につなぐだけ」では性能が上がらないという学びもありました。
LoRA(Low-Rank Adaptation。大規模モデルの一部だけを低コストで追加学習する手法)を複数用意しても、単純に接続するだけでは期待したような上乗せは起きませんでした。
つまり、つなげば勝てるほど単純ではありません。
重要なのは、どの内部表現を、どのタイミングで、どのモジュールに渡すか。そして、その結果をどう検証し、どう戻すかです。
ここに、NerveReflex の研究課題があります。
現時点で比較的確度が高いのは、速度面の優位です。
文字化を減らし、トークン生成を減らし、内部表現のまま処理する設計には、明確な速度メリットがあります。一方で、精度、汎用性、安定性、自然な異常データでの検証は、今後さらに確認が必要です。
おわりに
NerveReflex が目指すのは、Transformer を否定することではありません。
一つの巨大な知能だけですべてを処理するのではなく、複数のモデルやモジュールが、神経回路のように非言語の内部表現で協調する AI アーキテクチャを探ることです。
今回の実験では、3つの手がかりが見えました。
第一に、World Model と JEPA は、文字を介さずに世界や文脈の状態を予測し、サプライズを検知できます。
第二に、SLM の hidden state を直接読むことで、トークン生成なしに分類や構造化出力ができます。
第三に、Latent Reasoning は、思考過程を文字に展開せず、内部表現のまま高速に推論できる可能性を示しています。
これらはまだ個別の実験であり、完成したシステムではありません。
しかし、方向性は見えてきました。
AIが理解した内容を、毎回人間の言葉に戻さない。内部表現のまま推論し、検知し、判断し、協調する。
その先に、軽く、速く、経験から少しずつ適応する AI システムがあるのではないかと考えています。
次のステップは、SLM、World Model、JEPA、Latent Reasoning、進化的な学習モジュールを、より一貫した NerveReflex アーキテクチャとして接続することです。
業務文書の確認、異常検知、分類、ルーティング、現場判断の補助のように、まずは限定された実務タスクで効果を検証していきます。
特に、トークン生成を減らし、軽量な内部表現処理に置き換えられる領域では、コスト削減や作業時間の短縮につながる可能性があります。
つまり、実務で ROI につながりうる、軽くて速い AI システム を段階的に検証していくこと。
NerveReflex は、そのための最初の研究です。
付録: 使用したモデル・実験環境・出典
公開を前提とした記録として、本稿で触れた実験について、何を、どの環境で、どのソースで動かしたかを明記します。特に、他者が作ったものを動かしただけなのか、自分たちで訓練したのかを区別しています。いずれも GX10(NVIDIA Grace Blackwell ベースの単一マシン)上での実行です。
1. LeWorldModel
- モデル: LeWorldModel(約 15M パラメータの JEPA World Model)。学習済みチェックポイント
quentinll/lewm-pushtを使用。 - 出典: 公式実装
stable_worldmodel/stable_pretrainingの git main 版。論文は LeWorldModel(arXiv 2603.19312)、理論基盤の LeJEPA / SIGReg(arXiv 2511.08544)。 - 環境: 単一 GPU、
uv仮想環境(Python 3.10、torch 2.12+cu130)。PushT の expert データセットで評価。 - 私たちの関与: 学習済みモデルの評価実行のみ。成功率 94%。自前の訓練はしていません。
2. 法務契約レビューの異常検知 / リスク分類
- モデル: 意味表現の抽出に Gemma-3-4b-it。異常検知用に自前 Micro-JEPA(約 5M パラメータ)、リスク分類用に自前 classifier head を使用。
- 出典 / データ: JEPA と classifier head は NerveReflex 用の自前実装(Rust / candle)。学習データは公開コーパス CUAD(TheAtticusProject/cuad、CC BY 4.0)と、人工的に注入した異常例。
- 環境: GX10、自前訓練。
- 私たちの関与: 自前で訓練。JEPA の分離性能 AUC 0.97、risk classifier の比較動画を作成。ただし異常例は人工的に注入したものであり、自然な異常での再検証は今後の課題です。
3. Latent Reasoning の比較動画
- モデル: 公開学習済みチェックポイント
zen-E/CODI-llama3.2-1b-Instruct(Llama-3.2-1B ベース)。トークナイザ等の土台にはunsloth/Llama-3.2-1B-Instructを使用。 - 出典: CODI 公式実装。論文は CODI(EMNLP 2025、arXiv:2502.21074)。
- 環境: GX10(aarch64、torch 2.12+cu130)。
- 私たちの関与: 公開重みの評価・速度計測・動画化のみ。モデル自体は CODI 著者チームの成果です。
4. Latent Reasoning の自前訓練
- モデル: DeepSeek-R1-Distill-Qwen-1.5B を土台に、CODI 方式で latent 化を自前訓練(LoRA、latent ステップ数 6、射影層あり)。
- 出典: CODI 公式実装を流用。
- 環境: GX10、約 4 時間(約 0.25 epoch)。
- 私たちの関与: 自前訓練。速度優位(最大で約 40 倍)は確認できましたが、計算資源が足りず精度は約 42.5% で頭打ちでした。途中、学習率が高すぎて一度モデルが崩壊する失敗もありました。本稿の動画には、この自前モデルではなく、公開 Llama-1B ベースの CODI を使用しています。
この記事についてのLinkedIn投稿でコメントや意見を共有できます。
LinkedInで議論する