NerveReflex — Research on an AI Architecture That Cooperates Without Language
Challenge
Today's AI systems, when having models cooperate, often convert their work back into human language. One model outputs text, and another model reads it again. This approach is easy to understand, but it produces latency, cost, information loss, and format breakage from token generation. In addition, LLMs tend to return plausible-looking answers even for unlearned inputs, and the mechanism for autonomously re-learning from operational experience is still weak.
Solution
NerveReflex is an AI architecture in which AI models cooperate through non-verbal internal representations. Like a human neural reflex, it conveys pre-verbal signals at low latency and lets multiple models share reasoning, detection, and judgment by leveraging their respective strengths. By compensating for each model's weaknesses with another model's strengths, the aim is to build an AI system that is, as a whole, faster, lighter, able to notice unlearned inputs, and able to adapt from experience.
Result
We validated the NerveReflex idea on legal contract review and latent reasoning. For legal contract risk classification, reading an SLM (Small Language Model)'s internal representation directly produced structured output with zero generated tokens in about 0.07 seconds. Further stacking JEPA (Joint Embedding Predictive Architecture) on the same internal representation detected clauses that deviate from the normal distribution at AUC 0.97. This shows that by sharing internal representations, 'fast judgment' and 'awareness of unlearned or anomalous inputs' can be complemented by separate modules. For latent reasoning, non-verbal internal-representation reasoning solved the same problem about 14x faster than text-based reasoning.
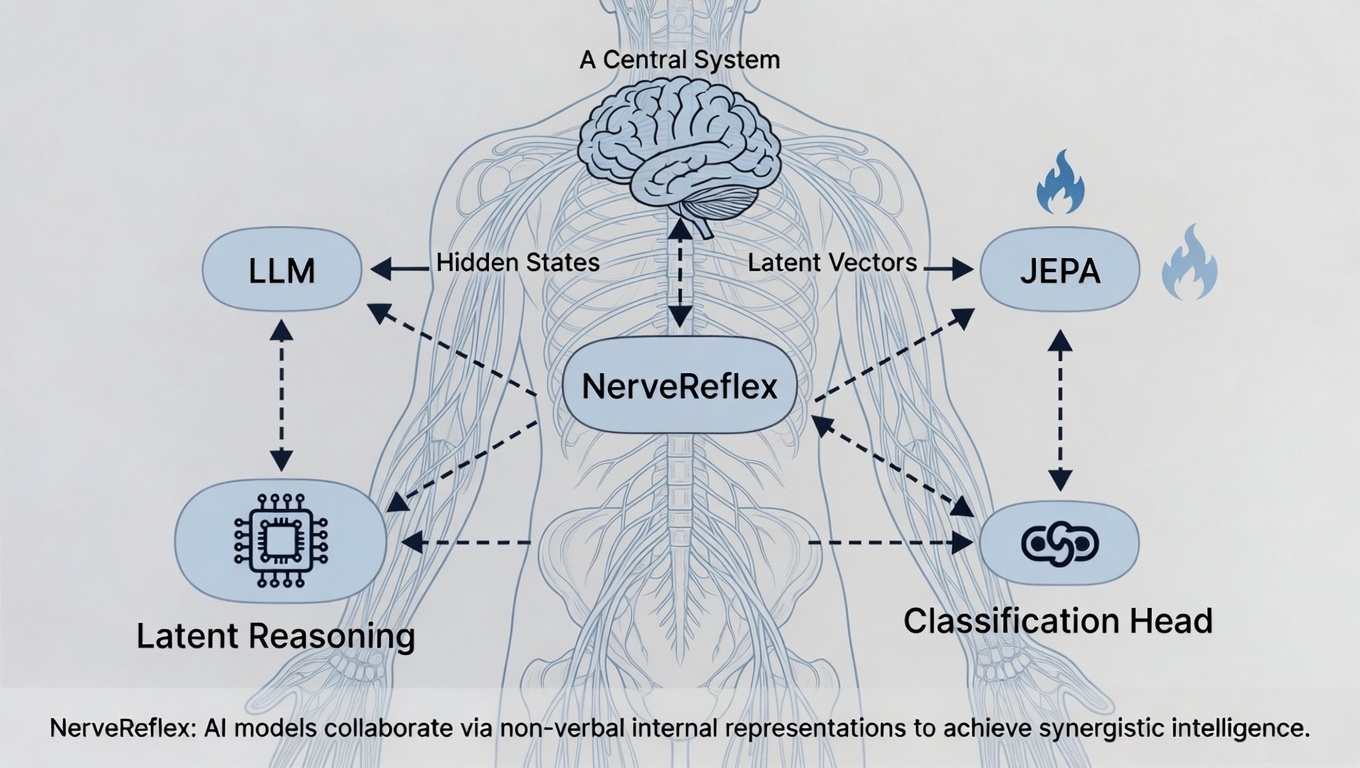
Introduction — What Is NerveReflex
In this article, I call this direction NerveReflex.
NerveReflex is an AI architecture in which AI models cooperate through non-verbal internal representations, much like a neural circuit.
The human body does not put everything into words before it acts.
The moment you touch something hot, your hand pulls back. The moment you are about to fall, your foot moves. The moment a ball flies toward you, your body reacts.
These do not happen after you have thought in language. A neural circuit transmits signals at low latency, and the brain, nerves, and muscles work together toward a single goal.
NerveReflex is an attempt to bring this idea into AI architecture.
Instead of converting what an AI has understood back into human language, we treat it as a hidden state (the numerical representation a model holds internally after processing an input) or a latent vector (an internal representation that compresses meaning or features).
We then use that internal representation to perform reasoning, classification, anomaly detection, judgment, and cooperation between models.
This is not an attempt to deny existing LLMs or the Transformer.
If anything, it is built on top of the strengths of LLMs and the Transformer. LLMs have overwhelming strengths in language understanding, knowledge compression, prose generation, and code generation. On the other hand, World Models (models that hold the state of the outside world or context internally and predict what happens next) have strengths in predicting world state and detecting surprise, and Latent Reasoning (reasoning that advances as internal representations rather than text) holds the potential for fast non-verbal reasoning. Evolutionary learning models hold the potential to adapt from experience.
What matters is not that any one of them completely replaces the others.
What NerveReflex aims for is not to have each model compete on its own, but to have them cooperate at a layer of internal representations that does not pass through language.
What also matters here is that the goal of cooperation is not merely speed.
LLMs have great strengths in language understanding and knowledge processing. On the other hand, they are weak at saying “I don’t know” for inputs they have not learned, and the mechanism to autonomously re-learn from operational experience is also still weak.
So we connect a JEPA-style model non-verbally to the internal representation an LLM or SLM has produced. JEPA can measure, as energy, how far an input deviates from the learned normal distribution. In other words, even in situations where an LLM alone would return a plausible-looking answer, another model may be able to detect that “this is close to unlearned” or “this is not the usual case.”
Furthermore, if we accumulate such high-energy inputs, we can pick up the new cases that appear in the field and use them as candidates for re-learning or adaptation. This is a doorway to evolutionary learning that is hard to reach with a fixed LLM alone.
In other words, NerveReflex is a design in which the weakness of one model is compensated by the strength of another. JEPA compensates for the LLM’s weakness against unlearned inputs, latent reasoning compensates for the slowness of text-based reasoning, and a classification head compensates for the weight of routine judgment. If multiple models cooperate at the level of internal representations like this, we may be able to build a mechanism that reduces the downsides of any single model while making use of each one’s strengths.
Put another way, this is not research on “building one giant model,” but research on an AI architecture in which multiple intelligent modules cooperate like a neural circuit and compensate for each other’s weaknesses.
Why “Going Back to Words” Is a Problem
In today’s AI agents and multi-model configurations, natural language is often used for the exchange between models.
For example, one model reads a contract and outputs in text, “This clause is of medium risk.” The next model reads that text and makes another judgment.
This is easy for humans to understand. But seen as an AI system, there is a lot of waste.
First, generating text takes time. An LLM usually outputs characters one token at a time. Just to emit a short JSON, the model has to be run dozens of times.
Second, token generation has a cost. The more a company uses AI in operations, the more cost grows from input tokens, output tokens, long conversation histories, and the trial-and-error of agents.
Third, when you go back to text, information is lost. Internally, the model holds context, meaning, structure, ambiguity, and confidence as high-dimensional internal representations. But once compressed into a short piece of text, part of that information is lost.
Fourth, formats break. You want a JSON, but a code block gets attached, extra explanations get mixed in, or the result is in a form that cannot be parsed.
In other words, a design that goes back to human language every time AIs cooperate is easy to understand, but tends to be slow, heavy, and unstable.
NerveReflex changes this part.
Rather than converting what a model has understood back into text every time, we pass the internal representation on to the next step. We verbalize only when needed. By doing so, we are testing whether it is possible to build an AI system that is lower-latency, lighter, and more stable.
NerveReflex’s Basic Policy
NerveReflex’s basic policy is to make use of the strengths of existing models while carving out the parts where verbalization is not needed.
For example, an SLM has the ability to understand text and images as meaning. We use that ability as is.
However, the result of that understanding does not have to be passed every time to the LM Head (Language Model Head — the final layer that converts the internal representation into per-vocabulary probabilities and selects the next token) and emitted as text.
A normal LLM passes the hidden state to the LM Head and generates text.
In NerveReflex, we bypass the LM Head except where it is needed.
That is, we directly use the hidden state, which is the result of the model understanding the input. We stack a classification head on top of it, run JEPA-based anomaly detection on it, or pass it on to another model.
The JEPA referred to here is a model that, rather than directly generating images or text, predicts in a low-dimensional space of meaning “what will happen next” or “is this state natural.”
NerveReflex’s idea can be organized as follows.
- Understanding: an SLM or LLM reads the input and produces an internal representation as a hidden state.
- Judgment: a classification head reads the required label or structured information from the hidden state.
- Detection: JEPA or an energy-based model looks at whether the internal representation deviates from the normal distribution.
- Reasoning: Latent Reasoning advances thought as latent vectors instead of unfolding it as text.
- Cooperation: different models or modules cooperate through internal representations rather than natural language.
This is not just about lining up existing models side by side.
What we aim for is a design in which AI models cooperate through internal signals that are like a neural circuit.
Step One: A Model That Predicts the World — Validating LeWorldModel
The first subject of research was LeWorldModel (a JEPA World Model).
An LLM basically predicts the next token. That is, it generates the continuation of text as a string.
LeWorldModel, by contrast, does not directly generate pixels or characters. It maps the state of the world into a latent space (a space of meaning representations that compresses high-dimensional inputs) and predicts “what happens next” within that space.
Its characteristics are as follows.
- Rather than generating pixels or characters, it predicts the future in a low-dimensional latent space.
- It is a small model of about 15M parameters, manageable on a single GPU.
- It solves a physical task called PushT through planning in the latent space.
PushT is the task of pushing a T-shaped block to a target position. It looks simple to a human, but for an AI it requires understanding the object’s position, orientation, contact, and how force is applied.
In this task, CEM (Cross-Entropy Method — an optimization method that tries multiple action candidates, keeps the promising ones, and improves the plan) is used to plan actions in the latent space.
Running the publicly available pre-trained sample model on a single GPU at hand, behavior with a 94% success rate on the PushT task was confirmed.
Prediction and Surprise Detection
The value of LeWorldModel lies mainly in two things.
The first is prediction.
It performs the future prediction “if the current state is like this, the next should be like that” in the latent space rather than in characters. This is the core of a World Model.
The second is surprise detection.
Surprise here means “how unnatural is this, as seen from the learned world.” In JEPA and energy-based models (models that measure how natural a state or combination is, using a score called energy), the more unnatural a state, the higher its energy.
In other words, the model can not only predict the future but also detect events that are physically or contextually impossible.
This can become an important component of NerveReflex.
In neural reflex too, the body reacts instantly to abnormal stimuli. The moment you touch something hot, your hand pulls back before you have thought in words. In the same way, in an AI system as well, one can imagine a design in which a lightweight detection module reacts the moment an internal representation deviates from the normal distribution.
Application: Evaluating Business Documents Through Internal Representations
When people hear “World Model,” they often imagine the physical world or robotics.
However, NerveReflex’s idea can also be applied to business documents.
Contracts, applications, internal memos, logs, and inquiry texts each have their own “normal pattern.” Even if they look complex as text, viewed as internal representations, it may be possible to distinguish a normal distribution from one that deviates from it.
As the first business application, I tried legal contract review.
The flow is as follows.
First, I input a contract clause into Gemma, an SLM. Gemma reads the text and creates a hidden state — that is, an internal representation.
Normally, this hidden state would be passed to the LM Head and converted into characters as the next token. But the goal this time is not text generation. I want to see whether the contract clause deviates from the usual pattern.
So I pass the internal representation Gemma has produced to JEPA, and JEPA measures the energy.
The division of roles is as follows.
- SLM (Gemma): reads the contract clause and converts it into an internal representation.
- JEPA: measures, as energy, how far that internal representation deviates from the distribution of normal contract clauses.
In other words, it is a configuration where text understanding is handled by the SLM and anomaly detection is handled by JEPA.
In this experiment, I checked whether “normal contract clauses” and “anomalous clauses” could be separated by energy. As a result, separation at AUC 0.97 was confirmed.
AUC is a metric indicating how well a classification model separates normal from anomalous. The closer to 1.0, the higher the separation performance; 0.5 indicates a state close to random.
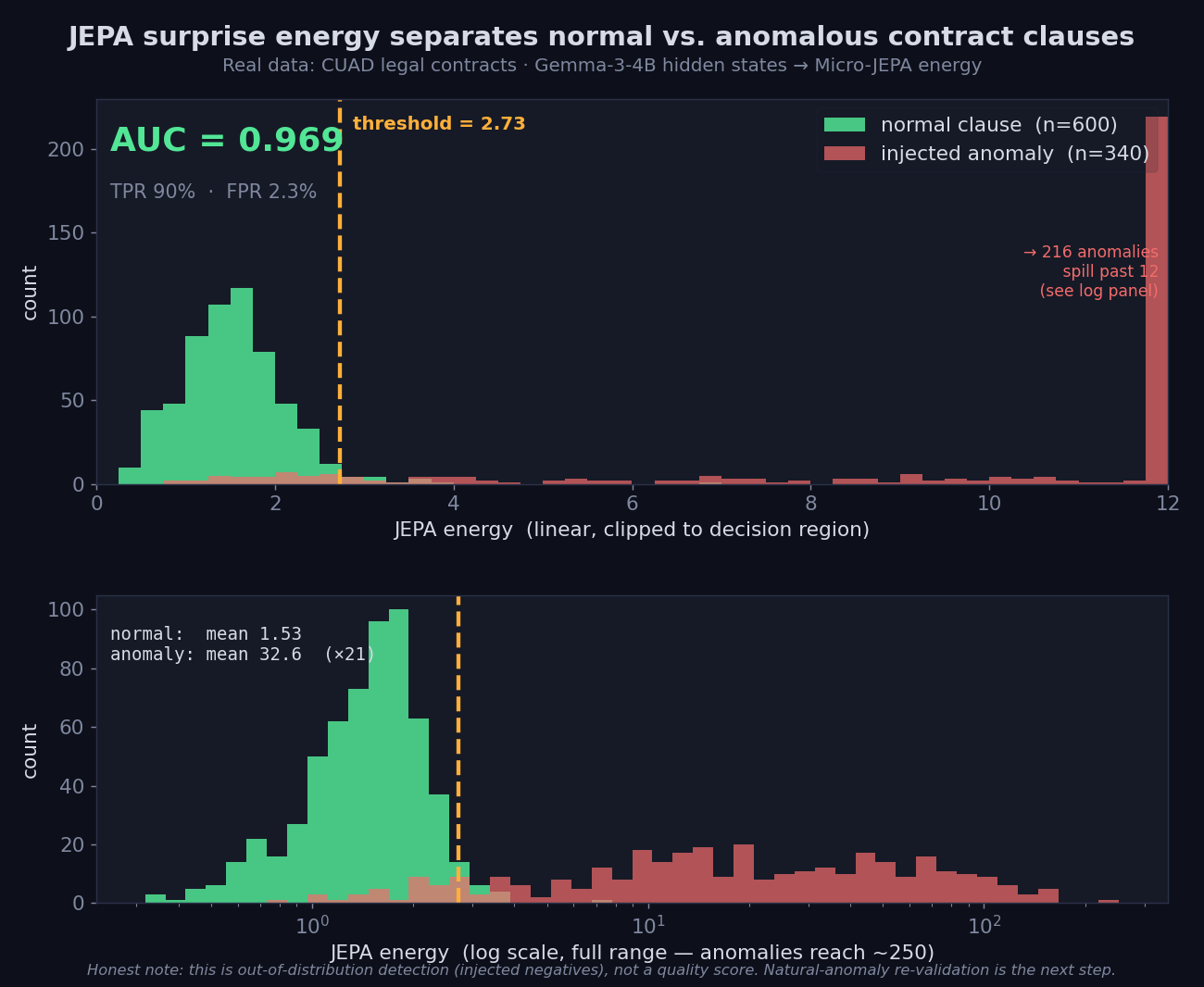
Most normal clauses gathered at low energy, while anomalous clauses spread out to the high-energy side. By setting a threshold, the separation performance was AUC 0.97, TPR (the rate of correctly detecting anomalies) 90%, and FPR (the rate of mistakenly rejecting normal ones) 2.3%.
That said, this does not score “how good a contract is.”
What is being looked at is merely “whether it deviates from the normal distribution.” Also, since the anomalous data was artificially created and mixed in, re-validation on natural anomaly data remains necessary.
Even so, by combining the SLM and JEPA at the level of internal representations, the possibility of evaluating business documents without text generation came into view.
Classifying Without Emitting Text — Judgment That Does Not Go Through the LM Head
Next, I tried risk classification on the same contract clauses.
In the usual method, you ask Gemma:
“Classify this clause and output the result as JSON.”
Then Gemma generates a JSON like {"risk_level": "medium", ...} as text. This is the usual way of using an LLM.
In NerveReflex, however, I take a different approach.
I pass the same clause through Gemma, then take the resulting hidden state. That hidden state is fed into a small classification head. The classification head directly predicts items such as risk_level, clause_type, and needs_review.
In this approach, the model is not generating the string “JSON” at all.
The classification head is simply reading the internal representation, which is the result of Gemma understanding the clause. The final JSON is deterministically assembled on the program side.
A comparison gives the following.
| Comparison | Plain Gemma (output as text) | NerveReflex (classify by internal representation) |
|---|---|---|
| How output is produced | Generates JSON as text | Passes hidden state through a classification head |
| risk_level result | medium (correct) | medium (correct) |
| Generated tokens | 37 tokens | 0 tokens |
| Model executions | 38 (1 prefill + 37 decode) | 1 |
| Time taken | about 5 sec | about 0.07 sec |
| Output format | Free text, needs parsing, can break | Structured JSON, no parsing |
What is important here is not cleverness.
It is that the same answer is produced, yet one side generated not a single token.
On the left side, even for a short JSON, characters have to be generated one token at a time. On top of that, code blocks and extra explanations can get mixed in.
On the right side, the same classification result is obtained by reading the hidden state — the result of Gemma understanding the clause — just once. The output format is also fixed on the program side, so it is harder to break.
What matters in practice is that classification, extraction, and detection like this run in large volumes. If the verbalization cost per item can be reduced, overall cost and latency drop substantially.
What is even more important is that another module can be stacked on top of the same hidden state.
The classification head reads “which risk class this clause falls into.” JEPA, on the other hand, looks at “whether this clause deviates from the normal distribution.”
In other words, both classification and anomaly detection — two different kinds of judgment — can be stacked on the same internal representation.
This is the central idea of NerveReflex.
Rather than a single model outputting everything as words, multiple specialist modules cooperate and react on top of an internal representation.
Step Two: Reasoning with Internal Representations Instead of Text — Latent Reasoning
The next clue was to separate reasoning itself from text.
A normal reasoning model writes a long thought process before producing an answer. For example, a model like DeepSeek-R1 emits a reasoning trace of hundreds to thousands of tokens as text, and then produces the final answer.
This method is powerful.
By thinking in text, intermediate calculations, hypotheses, corrections, and checks can be made explicit. It is readable for humans and self-correction is also easier.
On the other hand, it has a weakness.
As long as it thinks in text, the more it thinks, the more tokens it produces. The output grows longer, it gets slower, and inference cost increases.
In contrast, Latent Reasoning (reasoning that, instead of outputting the thought process as text, advances as internal representations such as hidden states or latent vectors) is an approach that does not output thought as text but advances it as internal representations.
One representative example is CODI. Instead of unfolding the intermediate reasoning process as natural-language tokens, CODI treats it as continuous latent vectors.
There are two key points.
- Without unfolding thought into text, advance it as latent thought (latent thought vectors).
- At the end, output only the answer as language tokens.
In other words, no long thought process appears on screen. The model advances short latent steps internally and outputs only the answer at the end.
This is close to NerveReflex’s idea.
Without converting everything back to text, advance things as internal representations where they can be advanced as internal representations. Verbalize only when needed.
Seeing It in Video — Same Problem, Same GPU
Note: the model in this video is CODI’s publicly released pre-trained checkpoint (Llama-3.2-1B based). The model itself is the work of the CODI authors’ team; in this article, I only performed behavior confirmation and speed measurement using it.
| Comparison | Token CoT (reason in text) | Latent (reason in internal representations) |
|---|---|---|
| Reasoning method | Writes out 215 tokens of thought as text | Reasons internally with 6 latent vectors |
| Output | After emitting the thought process, outputs the answer 18 | Immediately outputs only the answer 18 |
| Result | Correct | Correct |
| Speed | about 3.4 sec | about 0.25 sec |
| Speed difference | Baseline | about 14x faster |
The Latent Reasoning on the right is a method of “think silently, then put only the answer into words.”
While the Token CoT on the left is still writing its thoughts, the right side has already produced the answer. This gap shows the speed advantage of reasoning that does not unfold into text.
That said, Latent Reasoning is not a cure-all.
Text-based reasoning has the strength of allowing you to rewrite calculations midway, try a different approach, or double-check. On hard problems, this explicit self-correction pays off.
In Latent Reasoning, on the other hand, the number of thought steps is often fixed. It suits short reasoning, but can be at a disadvantage on long deliberation or multi-stage problems.
In other words, Latent Reasoning is not a complete replacement for text-based reasoning.
However, in settings where speed matters — short reasoning, classification, routing, anomaly detection, and simple judgments — it can be a useful component.
In NerveReflex, such Latent Reasoning is positioned as part of the reflex-like internal processing.
What NerveReflex Aims For
The experiments so far converge in a single direction.
What NerveReflex aims for is not to build one giant general-purpose model.
Nor is it to simply line up existing models side by side.
What we aim for is an architecture in which AI models cooperate as internal representations, without passing through language.
In the human body, the brain, nerves, muscles, and sensory organs each have different roles and yet cooperate toward a single goal. They are not explaining everything to each other in words. They react at low latency through neural signals.
NerveReflex takes the same approach.
- One model understands text or images.
- One module classifies.
- One module detects anomalies.
- One module performs short reasoning as internal representations.
- One module picks up inputs that deviate from past experience and treats them as candidates for re-learning.
Rather than stitching these together one by one in natural language, they are made to cooperate at the layer of internal representations.
If this idea holds, it may lead not only to applications of existing models but also to new model designs.
For example, a model that, from the outset, places at its center not “language generation” but the transmission of internal representations, reflex-like detection, low-latency judgment, and adaptation from experience.
This is not a story of immediately replacing the successor of LLMs.
LLMs will remain important. Their strengths in language understanding, knowledge processing, explanation generation, and code generation remain large.
However, not every part of an AI system needs to be entrusted to the LLM’s text generation.
NerveReflex is an attempt to place World Models, JEPA, Latent Reasoning, and evolutionary learning modules around the LLM, and to have them cooperate through internal representations, in order to build an AI system that is lighter, faster, and closer to the field.
Still at the Validation Stage
Of course, this is not yet a completed architecture.
At present, it is at the stage of accumulating hypotheses and partial experimental results.
The biggest technical challenge is how to align internal representations across different models.
The hidden state of one model and the hidden state of another, even if they look like the same “internal representation,” do not have matching coordinate systems. Simply connecting them does not guarantee that meaning gets through.
For this reason, latent space alignment (the processing that maps the internal representations of different models to one another) becomes necessary.
There is also the lesson, from past experience, that “simply connecting specialist LoRAs” did not improve performance.
Even when multiple LoRAs (Low-Rank Adaptation — a method of additionally training only part of a large model at low cost) were prepared, simply connecting them did not produce the boost I expected.
In other words, it is not as simple as winning just by connecting them.
What matters is which internal representation to pass, at what timing, to which module — and how to validate and how to feed back the result.
This is where the research questions of NerveReflex lie.
What is relatively certain at present is the advantage in speed.
A design that reduces verbalization, reduces token generation, and processes as internal representations has a clear speed benefit. On the other hand, accuracy, generality, stability, and validation on natural anomaly data still need further confirmation.
Conclusion
What NerveReflex aims for is not to deny the Transformer.
Rather than processing everything with one giant intelligence, it is to explore an AI architecture in which multiple models and modules cooperate, like a neural circuit, through non-verbal internal representations.
In the experiments this time, three clues came into view.
First, World Models and JEPA can predict the state of the world or a context without going through text, and can detect surprise.
Second, by reading an SLM’s hidden state directly, classification and structured output are possible without token generation.
Third, Latent Reasoning shows the possibility of reasoning quickly, without unfolding the thought process into text, while staying in the internal representation.
These are still individual experiments, not a completed system.
But the direction has come into view.
What an AI has understood is not converted back into human language every time. It reasons, detects, judges, and cooperates as an internal representation.
Beyond that, I believe there may be an AI system that is light, fast, and able to adapt little by little from experience.
The next step is to connect SLMs, World Models, JEPA, Latent Reasoning, and evolutionary learning modules into a more coherent NerveReflex architecture.
For tasks such as checking business documents, anomaly detection, classification, routing, and assisting field judgment, the plan is to start by validating effectiveness on a limited set of practical tasks.
In particular, in areas where token generation can be reduced and replaced with lightweight internal-representation processing, there is potential for cost reduction and shorter work time.
In other words, the goal is to incrementally validate a light, fast AI system that could lead to ROI in practice.
NerveReflex is the first piece of research toward that goal.
Appendix: Models Used, Experimental Environment, and Sources
As a record intended for publication, I make clear what was run, in what environment, and from what source for the experiments touched on in this article. In particular, I distinguish whether I merely ran something built by others or trained it myself. All were run on the GX10 (a single machine based on NVIDIA Grace Blackwell).
1. LeWorldModel
- Model: LeWorldModel (a JEPA World Model of about 15M parameters). Used the pre-trained checkpoint
quentinll/lewm-pusht. - Source: the official implementations
stable_worldmodel/stable_pretraining, git main version. Papers: LeWorldModel (arXiv 2603.19312), and the theoretical foundation LeJEPA / SIGReg (arXiv 2511.08544). - Environment: single GPU,
uvvirtual environment (Python 3.10, torch 2.12+cu130). Evaluated on the PushT expert dataset. - Our involvement: evaluation runs of the pre-trained model only. 94% success rate. We did not do our own training.
2. Anomaly Detection / Risk Classification for Legal Contract Review
- Model: Gemma-3-4b-it for meaning-representation extraction. On top of it, our own Micro-JEPA (about 5M parameters) for anomaly detection and our own classifier head for risk classification.
- Source / Data: both the JEPA and the classifier head are NerveReflex’s own implementation (Rust / candle). Training data is the public corpus CUAD (TheAtticusProject/cuad, CC BY 4.0) and artificially injected anomaly examples.
- Environment: GX10, trained by us.
- Our involvement: trained by us. JEPA separation performance AUC 0.97; the risk-classifier comparison video. However, the anomaly examples were artificially injected, so re-validation on natural anomalies is a future task.
3. Latent Reasoning Comparison Video
- Model: the publicly released pre-trained checkpoint
zen-E/CODI-llama3.2-1b-Instruct(Llama-3.2-1B based). The ungated mirrorunsloth/Llama-3.2-1B-Instructwas used as the base for the tokenizer and so on. - Source: the official CODI implementation. Paper: CODI (EMNLP 2025, arXiv:2502.21074).
- Environment: GX10 (aarch64, torch 2.12+cu130).
- Our involvement: evaluation, speed measurement, and video production of public weights only. The model itself is the work of the CODI authors’ team.
4. Our Own Training of Latent Reasoning
- Model: based on DeepSeek-R1-Distill-Qwen-1.5B, latent-ized by us in the CODI manner (LoRA, latent steps 6, with a projection layer).
- Source: reused the official CODI implementation above.
- Environment: GX10, about 4 hours (about 0.25 epoch).
- Our involvement: trained by us. We could confirm the speed advantage (up to about 40x), but due to insufficient compute, accuracy plateaued at about 42.5%. Along the way, there was also a failure where the learning rate was too high and the model collapsed once. The video in this article uses the public Llama-1B-based CODI from item 3 above, not this self-trained model.
Join the conversation on LinkedIn — share your thoughts and comments.
Discuss on LinkedIn