PHPとTwitter APIで感情分析ツールを構築する

はじめに
「人々の感情をデータとして可視化できたら、どのようなことが見えてくるのだろう」 — そんな素朴な問いが、このプロジェクトの出発点でした。
感情分析(Sentiment Analysis)は、テキストデータからポジティブ・ネガティブといった感情の傾向を定量的に判定する技術です。この技術を活用することで、以下のような応用が考えられます。
- 株価と世論の相関分析 — 市場センチメントの可視化
- ブランドイメージの定量評価 — SNS上の評判モニタリング
- 製品・サービスのフィードバック分析 — ユーザーの声を構造的に把握
- 政策に対する世論の把握 — 社会的な反応の傾向分析
本記事では、Twitterのツイートを対象に、PHPで辞書ベースの感情分析ツールを構築した過程を紹介します。リアルタイムに投稿されるツイートは、人々の率直な感情が表れやすく、感情分析の対象として適していると考えました。
ソースコードは GitHub で公開しています。
感情分析の3つのアプローチ
感情分析の手法は、大きく3つに分類できます。
1. 辞書ベース(ルールベース)
あらかじめ感情スコアが付与された辞書(感情辞書)を用意し、テキスト中の単語をスコアリングする手法です。仕組みが明快で実装も比較的容易なため、感情分析の入門として最適です。
2. 機械学習ベース
Doc2Vecなどの手法で文章をベクトル化し、文脈から感情を判定します。2010年代以降に普及した手法で、辞書に依存せず文脈を考慮できる点が強みです。
3. クラウドサービス
各社が提供するAIベースの感情分析APIを利用する方法です。
本記事では 1. 辞書ベースのアプローチ を採用しました。仕組みが透明で、感情分析の基本原理を理解するのに最も適していると判断したためです。
辞書ベース感情分析の仕組み
辞書ベースの感情分析は、以下の3ステップで構成されます。
ステップ1:ツイートの取得
Twitter APIを使い、指定したキーワードに関連する最新のツイートをプログラムで自動取得します。
ステップ2:形態素解析
取得したツイートに対して形態素解析を行います。形態素解析とは、文章を意味を持つ最小単位(形態素)に分割し、品詞を判定する処理です。
例えば、「今日はとても良い天気です」という文を形態素解析すると、次のように分割されます。
| 形態素 | 品詞 |
|---|---|
| 今日 | 名詞 |
| は | 助詞 |
| とても | 副詞 |
| 良い | 形容詞 |
| 天気 | 名詞 |
| です | 助動詞 |
日本語の形態素解析には MeCab を使用しました。英語は単語がスペースで区切られるため比較的簡単に分割できますが、日本語は単語の境界が不明確なため、専用の解析エンジンが必要です。
ステップ3:感情辞書によるスコアリング
形態素解析で分割した各単語を感情辞書と照合し、スコアを算出します。
感情辞書には、東京工業大学の高村教授が公開されている Semantic Orientations of Words を使用しました。この辞書では、各単語に -1.0(ネガティブ)から +1.0(ポジティブ)の実数値が割り当てられています。
例えば、先ほどの例文の場合:
| 単語 | スコア |
|---|---|
| 今日 | +0.021 |
| 良い | +1.000 |
| 天気 | -0.017 |
合計スコアは約 +1.003 となり、この文はポジティブな感情を表していると判定されます。
環境構築
前提環境
- CentOS 6.8
- Apache 2.2
- PHP 5.6
MeCabのインストール(日本語形態素解析)
MeCab は、日本語の形態素解析エンジンとして広く利用されているオープンソースツールです。
# MeCab本体のインストール
cd /usr/local/src
wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE"
tar xvfz mecab-0.996.tar.gz
cd mecab-0.996
./configure --with-charset=utf8
make
make install
# IPA辞書のインストール
cd /usr/local/src
wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM"
tar zxfv mecab-ipadic-2.7.0-20070801.tar.gz
cd mecab-ipadic-2.7.0-20070801
./configure --with-charset=utf8
make
make install次に、PHPからMeCabを呼び出すための拡張モジュールをインストールします。
# php-mecab拡張モジュール
cd /usr/local/src
git clone https://github.com/rsky/php-mecab.git
cd php-mecab/mecab/
phpize
./configure --with-php-config=/usr/bin/php-config --with-mecab=/usr/bin/mecab-config
make
make test
make install
# php.iniに拡張モジュールを登録
# extension=/usr/lib64/php/modules/mecab.so を追記
# Apacheを再起動
service httpd restartPHPからMeCabが正しく動作するか確認します。
<?php
$options = array('-d', '/usr/local/src/mecab-ipadic-2.7.0-20070801');
$mecab = new \MeCab\Tagger($options);
$text = "テスト文章";
$node = $mecab->parseToNode($text);
while ($node) {
var_dump($node->getSurface());
var_dump($node->getFeature());
$node = $node->getNext();
}感情辞書の準備
東京工業大学・高村教授の Semantic Orientations of Words をダウンロードし、プロジェクトディレクトリに配置します。この辞書は、岩波国語辞典(日本語)およびWordNet(英語)から抽出された語彙に対し、感情の方向性(ポジティブ/ネガティブ)が数値で付与されています。
Twitter APIの有効化
Twitter APIを利用するには、Twitter Developer Portal でのアプリケーション登録が必要です。
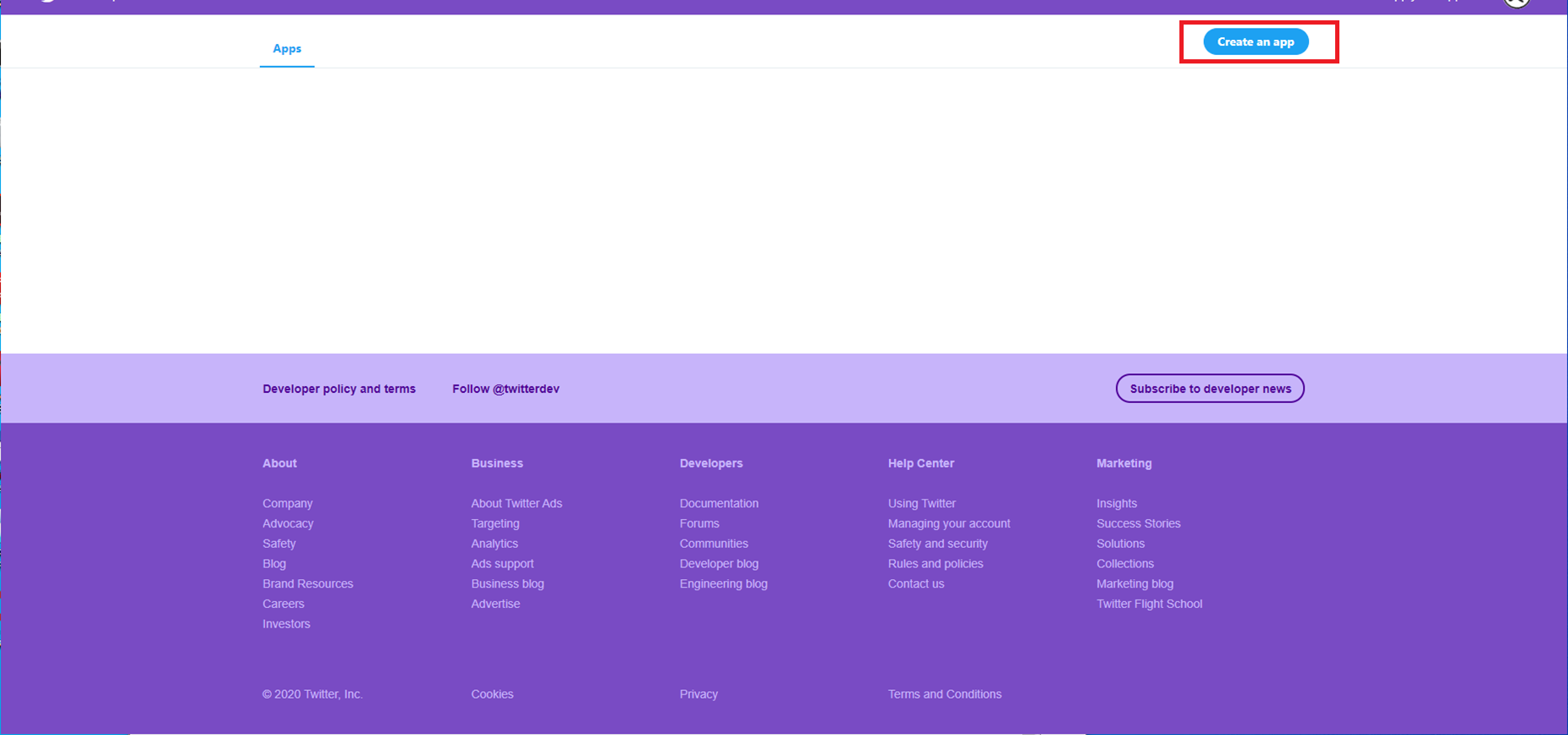
主な手順は以下の通りです。
- Twitter Developerサイトで開発者アカウントを申請
- 利用目的を記入し、審査を受ける
- 承認後、アプリケーションを作成
- 以下の4つの認証情報を取得する
- API Key
- API Secret Key
- Access Token
- Access Token Secret
これらの認証情報は、後述するPHPプログラムの設定ファイルで使用します。
TwitterOAuthライブラリのインストール
PHPからTwitter APIを操作するためのOAuth認証を簡素化するライブラリとして、abraham/twitteroauth を使用しました。
# Composerのインストール
curl -sS https://getcomposer.org/installer | php
mv composer.phar /usr/local/bin/composer
# TwitterOAuthライブラリのインストール
cd /path-to-project-directory/
composer require abraham/twitteroauth実装
ソースコードの全体は GitHub で公開しています。ここでは主要な部分を解説します。
設定ファイル(config.php)
Twitter APIの認証情報と解析パラメータを定義します。
<?php
// Twitter API認証情報
define('TWITTER_API_KEY', 'your-api-key');
define('TWITTER_API_SECRET', 'your-api-secret');
define('ACCESS_TOKEN', 'your-access-token');
define('ACCESS_SECRET', 'your-access-secret');
// 検索件数
define('SEARCH_COUNT', 100);
// 形容詞のみを対象とするか(1: 形容詞のみ, 0: 全品詞)
define('PERMIT_ONLY_ADJECTIVE', 1);PERMIT_ONLY_ADJECTIVE を 1 に設定すると、感情を表す形容詞のみをスコアリング対象とします。形容詞は感情を直接的に表現する品詞であるため、ノイズを減らし分析精度を向上させる効果があります。
ツイートの取得(main.php)
入力されたキーワードで最新のツイートを検索します。
<?php
// TwitterOAuthインスタンスの生成
$obj = new TwitterOAuth(
TWITTER_API_KEY,
TWITTER_API_SECRET,
ACCESS_TOKEN,
ACCESS_SECRET
);
// Standard Search APIのパラメータ設定
$options = array(
'q' => $keyword, // 検索キーワード
'lang' => 'en', // 対象言語
'result_type' => 'recent', // 最新のツイートを取得
'count' => SEARCH_COUNT // 取得件数
);
// APIリクエスト
$json = $obj->get("search/tweets", $options);Twitter APIの無料プランでは、15分あたり180リクエストの制限がある点に注意が必要です。
感情分析の実行
取得したツイートに対して、形態素解析と感情辞書によるスコアリングを実行します。
<?php
// Feelingsクラスのインスタンス生成
// PERMIT_ONLY_ADJECTIVE: 形容詞のみを対象とするかのフラグ
$feelings = new Feelings(PERMIT_ONLY_ADJECTIVE);Feelings クラスの内部では、以下の処理が行われます。
- 各ツイートをMeCabで形態素解析
- 分割された各単語を感情辞書と照合
- 一致した単語のスコアを合算
- 合計スコアの正負でポジティブ/ネガティブを判定
実行結果
プログラムを実行すると、まずキーワード入力画面が表示されます。
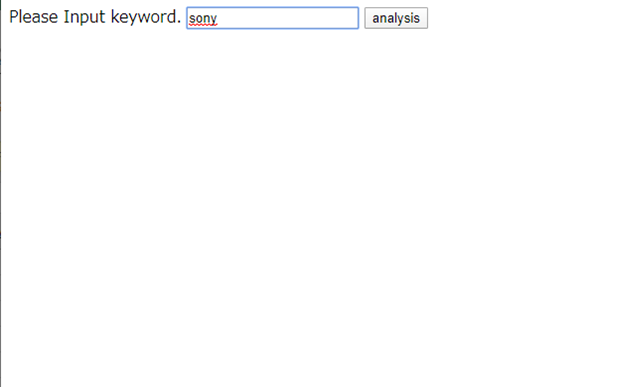
分析したいキーワードを入力してSubmitすると、ツイートの感情分析結果が表示されます。合計スコアが正であればポジティブ、負であればネガティブと判定されます。
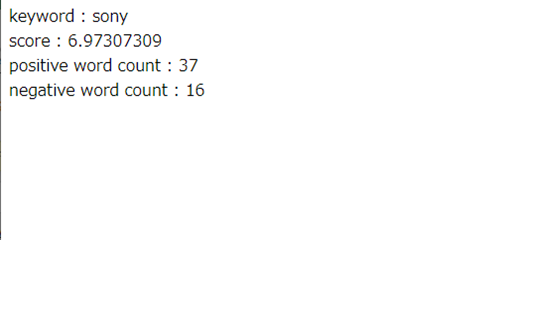
課題と展望
辞書ベースのアプローチは仕組みがシンプルで理解しやすい反面、いくつかの本質的な課題があります。
- 文脈の無視 — 「良くない」のような否定表現を正しく処理できない
- 辞書の網羅性 — 辞書に存在しない単語(新語・スラング)は評価できない
- 皮肉・比喩の検出 — 字面と真意が異なる表現に対応できない
より高精度な感情分析を実現するには、ディープラーニングを活用した手法が有効です。BERTやGPTのようなTransformerベースのモデルは、文脈を考慮した感情判定が可能であり、近年の感情分析研究の主流となっています。
このプロジェクトは、自然言語処理(NLP)の基礎を実践的に学ぶ良い機会となりました。辞書ベースの手法を自分の手で実装したことで、テキストから感情を抽出するプロセスの本質的な仕組みを深く理解できたと感じています。